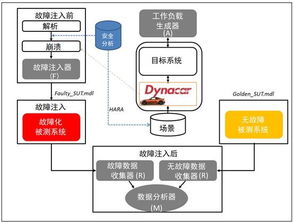
自动驾驶数据集生成:从采集到发布的完整流程
======================
引言--
随着人工智能和深度学习技术的飞速发展,自动驾驶技术也日新月异。数据集作为自动驾驶技术的核心资源,其生成和处理对于自动驾驶系统的性能至关重要。本文将详细介绍自动驾驶数据集生成的整个流程,包括数据采集、数据预处理、数据增强、数据标注、数据集构建、数据集可视化、数据集评估和数据集发布。
1. 数据采集-------
数据采集是自动驾驶数据集生成的第一步。在这一阶段,我们通过各种传感器(如摄像头、雷达、激光雷达等)收集大量的驾驶数据。这些数据可能包括车辆的实时位置、速度、方向,以及道路的几何形状、交通标志、行人和其他车辆的信息。这些数据将为后续的数据预处理和模型训练提供原始材料。
2. 数据预处理--------
在数据采集之后,我们需要进行数据预处理,以提高数据的可用性和准确性。数据预处理可能包括去噪、滤波、归一化、插值等操作。例如,我们可能需要对图像数据进行裁剪、缩放和旋转,以适应模型的输入要求。我们还需要对数据进行清洗,以去除无效或错误的数据。
3. 数据增强-------
为了提高模型的泛化能力,我们通常需要对数据进行增强。数据增强是通过随机变换原始数据(如旋转、缩放、翻转等)来创建新的数据的方法。这种方法可以帮助模型学习到更多样化的驾驶场景,从而提高其在真实环境中的表现。
4. 数据标注-------
对于自动驾驶任务,标注是极其重要的一步。我们需要对图像或视频数据进行注释,以指示车辆、行人、道路标记和其他关键对象的位置和类别。我们还需要为车辆的行为和决策提供标签,例如转向、加速或制动等。这些标注信息将用于训练和验证自动驾驶模型。
5. 数据集构建--------
在完成数据采集、预处理、增强和标注之后,我们可以开始构建自动驾驶数据集。在构建过程中,我们需要考虑到数据的多样性、准确性和规模。多样性意味着数据应该包含各种驾驶环境和驾驶条件,例如城市道路、高速公路、乡村道路,以及白天、夜晚和不同天气条件下的驾驶数据。准确性则意味着数据应该尽可能准确地反映真实的驾驶场景。规模则意味着我们需要有足够多的数据来训练和验证我们的模型。
6. 数据集可视化---------
可视化可以帮助我们更好地理解和分析数据。通过可视化工具,我们可以观察数据的分布、异常值和相关性。例如,我们可以将标注的数据以图像或视频的形式展示出来,以便更好地理解标注的过程和质量。我们还可以通过可视化来评估模型的性能和效果。
7. 数据集评估--------
为了确保我们的数据集质量,我们需要对数据进行评估。评估的指标可能包括数据的完整性、准确性、一致性等。例如,我们可以检查标注是否完整且准确,数据的分布是否符合实际情况等。我们还可以通过在验证集上评估模型的性能来间接评估数据集的质量。
8. 数据集发布--------
最后一步是发布我们的数据集。发布是为了让更多的研究人员和开发人员能够使用我们的数据集,从而推动自动驾驶技术的发展。在发布数据集时,我们需要考虑到数据的可访问性、安全性和可持续性。为了提高数据的可访问性,我们可以提供清晰的数据集说明文档和使用指南。安全性则意味着我们需要保护数据的隐私和安全,例如通过匿名化和加密技术。可持续性则意味着我们需要持续维护和更新我们的数据集,以适应技术的不断发展和变化。
结论--
自动驾驶数据集的生成是一个复杂且关键的过程,涉及到多个环节和大量的工作。从数据采集到发布,每个环节都关系到最终模型的性能和安全性。因此,我们需要认真对待每个环节,确保我们的数据集能够为自动驾驶技术的发展提供有力的支持。