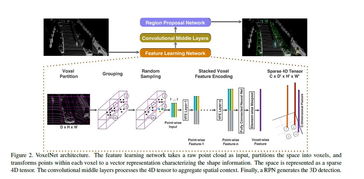
自动驾驶数据处理:从数据采集到模型部署的全面解析

===========================
一、自动驾驶数据处理概述

--------------
自动驾驶数据处理是指利用计算机视觉、深度学习等技术对大量车辆传感器数据进行处理和分析,以实现自主驾驶。它主要包括数据采集、预处理、标注与分类,数据增强与生成,模型训练与评估,部署与优化等过程。
二、数据采集与预处理

--------------
通过车辆上的各种传感器(如激光雷达、摄像头、GPS等)采集大量的数据。这些数据包括车辆周围的环境信息(如障碍物、交通信号灯、道路标志等)以及车辆自身的状态信息(如速度、加速度、转向角等)。
接下来是数据预处理阶段。这包括对数据进行清洗、去噪、滤波等操作,以去除无效和错误的数据,提高数据质量。同时,还需要对数据进行标准化或归一化处理,以使得不同来源的数据具有可比性。
三、数据标注与分类

-------------
在采集和预处理之后,我们需要对数据进行标注和分类。标注是指利用人工或自动方法对数据进行标记,以指示出各种物体和场景。例如,我们可能需要标记出车辆、行人、道路标志等物体。分类则是指将数据分为不同的类别,例如根据道路条件(干燥、湿滑、雪覆盖等)或交通状况(拥堵、畅通等)来分类。
四、数据增强与生成

------------
在标注和分类之后,我们需要进行数据增强和生成。数据增强是通过各种技术(如旋转、缩放、翻转等)来增加数据的多样性,以提高模型的泛化能力。生成则是通过模拟或合成方法来生成新的数据,以进一步扩大数据集。
五、模型训练与评估

-----------
接下来是模型训练和评估阶段。在这个阶段,我们使用训练集来训练我们的模型(如深度学习模型),并使用验证集来调整模型的参数和结构。一旦模型被训练好,我们还需要使用测试集来评估模型的性能。评估指标可能包括准确率、召回率、F1分数等。
六、部署与优化

---------
最后是模型的部署和优化阶段。部署是指将模型部署到实际运行的车辆中,以实现自动驾驶。优化则是指在部署后对模型进行持续的调整和改进,以适应环境和任务的变化。在这个阶段,我们还需要考虑模型的实时性、鲁棒性和可解释性等问题。
七、数据隐私与安全

-----------
在处理自动驾驶数据时,我们需要特别关注数据隐私和安全问题。我们需要遵守相关的法律法规,如欧盟的通用数据保护条例(GDPR)。我们需要采取措施来保护数据的安全,如加密存储和使用访问控制机制。我们需要确保模型的透明度和可解释性,以便于公众对自动驾驶系统的信任。
八、挑战与未来发展

-----------
尽管自动驾驶数据处理已经取得了显著的进展,但仍面临许多挑战。例如,如何处理复杂的环境和动态的交通情况,如何保证系统的可靠性和安全性,如何解决法规和伦理问题等。未来,随着技术的进步和法规的完善,我们期待自动驾驶能够更好地服务于人类社会。